K-Means Clustering
An unsupervised learning algorithm that groups similar data points into clusters based on their features and distance from cluster centers.
Understanding K-Means
K-means clustering is a method for grouping similar data points together—without being told what the groups should be.
For example, a business might use k-means clustering to group customers based on their purchase behavior—such as how often they shop, how much they spend, or what types of products they buy.
Even if the company hasn’t labeled customers as “loyal,” “new,” or “bargain-seeking,” the algorithm can still find patterns in the data. It looks at all the customer information and clusters together people who behave similarly—without needing to know in advance what those groups are called.
The result is that each customer is placed into a group with others who have similar shopping habits, helping the business create more targeted marketing strategies for each group.
Pick a number of groups you want—this is the “k” in k-means.
The algorithm picks k random points to act as starting centers (called centroids).
Each data point is assigned to the closest center, forming clusters.
The algorithm then moves the center of each cluster to the average (mean) of all the points in that cluster.
Steps 3–4 repeat until the centers don’t move anymore.
How it Works:
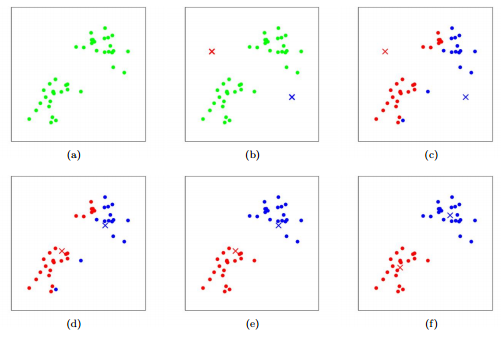
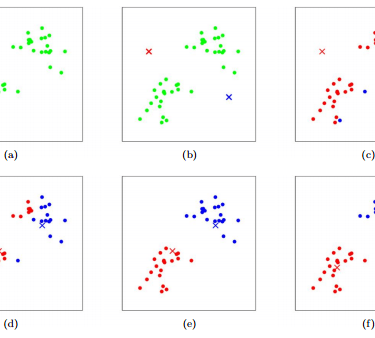
Image Source: Stanford CS221
K-means calculates the distance between data points and centroids based on euclidean distance.
For example, let's say there are three features being used to form the clusters:
Data point coordinate: (-0.35, 1.20, 0.15) -> (x1, y1, z1)
Centroid coordinate: (0.1, 0.9, 0.2) -> (x2, y2, z2)
Calculate the euclidean distance:
√[(x1 - x2)² + (y1 - y2)² + (z1 - z2)²]
Connect with Me!
LinkedIn: caroline-rennier
Email: caroline@rennier.com