Feature Engineering
Creating and reducing features is essential in machine learning because it shapes how effectively the model can learn meaningful patterns from the data.
Feature creation and feature reduction are two key strategies in preparing your data to improve model performance.
Feature creation involves building new, more meaningful features from the data you already have—like combining height and weight into BMI—to help the model recognize patterns more easily.
Feature reduction, on the other hand, means removing unnecessary, redundant, or unhelpful features so the model can learn faster and make more accurate predictions without being distracted by noise.
Together, these steps help focus the model on the most important information, boosting both speed and accuracy.
Feature Creation and ReductionOverview
Removing Unimportant Values
Removing unimportant features is one of the simplest and most effective ways to reduce dimensionality and improve model performance.
This process focuses on identifying variables that offer little to no predictive value, whether because they’re highly redundant, rarely change (low variance), or simply don’t impact the model’s output directly.
For instance, features that are loosely related to the target variable or contain excessive noise can confuse the model and lead to overfitting.
You can address this by removing highly correlated features (keeping only one from each correlated group) or by using model-based techniques like feature importance scores from Random Forests to rank and filter out less useful inputs.
This kind of pruning not only simplifies the dataset but also sharpens the model’s focus on the most meaningful signals.
An Example:
Imagine you’re building a model to predict whether a customer will buy a product. Your dataset includes these features:
Age
Income
Time spent on website
Favorite color
User ID
Sign-up date
After analyzing the data:
You find that “Favorite color” and “User ID” have no meaningful relationship with purchase behavior—one is arbitrary, the other is just a unique identifier.
“Sign-up date” has nearly the same value for most users (low variance), so it doesn’t help the model differentiate between buyers and non-buyers.
“Income” and “Time spent on website” are highly correlated, but you decide to keep only “Time spent” because it has a stronger connection to purchases based on feature importance scores.
By removing the unhelpful features, your model becomes more efficient, avoids distractions from noisy inputs, and is less likely to overfit.

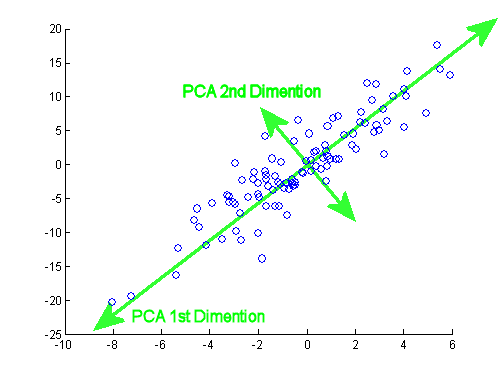
PCA (Principal Component Analysis)
Instead of looking at each original variable separately, PCA looks for combinations of variables that best describe the overall structure of the data.
These combinations are called principal components, and they are ranked based on how much variation (or information) they capture from the original dataset.
By reducing the number of dimensions (features), PCA makes it easier to visualize the data, speeds up modeling, and helps avoid overfitting.
The tradeoff is that the new components may not be as easily interpretable as the original features—but they often retain the underlying patterns that matter most for analysis or prediction.
An Example:
Let’s say you’re analyzing a dataset of cars with the following features:
Engine Size
Horsepower
Fuel Consumption
These features are often correlated (e.g., bigger engines usually mean more horsepower and higher fuel use). PCA would recognize this and combine them into one new feature that captures the general concept of “engine performance.”
Source: Raghavan - Medium
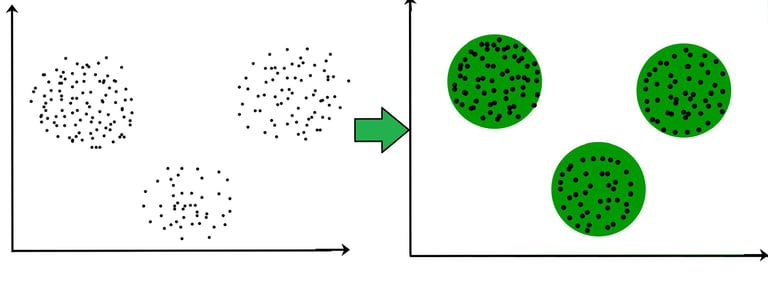
Clustering-based Reduction
Clustering can help reduce features by grouping similar data points and then representing each group with a summary.
For example, you might add a new feature indicating cluster membership and remove several original features that are no longer needed.
This reduces complexity while keeping meaningful differences between groups.
This can make your models faster, less prone to overfitting, and easier to interpret—especially when working with high-dimensional data.
Source: Geeks for Geeks
Interaction Terms
Interaction terms are new features created by multiplying or combining two or more existing features to capture the idea that their combined effect on the target variable is different from their individual effects.
In many real-world situations, variables don’t work in isolation - they influence the outcome together in complex ways.
Interaction terms help your model account for those combined effects, which basic linear relationships might miss.
An Example:
Suppose you’re predicting house price, and you have two features:
Size (in square feet)
Location (urban = 1, rural = 0)
Individually:
Bigger homes cost more.
Urban homes cost more.
But together:
A big house in the city may be way more expensive than just the sum of its size and location effects.
To capture that, you create an interaction term:
Interaction = Size × Location
So now the model can learn that size has a stronger effect in urban areas than rural ones.


Connect with Me!
LinkedIn: caroline-rennier
Email: caroline@rennier.com